
This post describes a bivariate data problem I introduced last month in my AP Statistics class, but it easily could have appeared in any Algebra 2 or PreCalculus course, particularly for those classes adapting to the statistics strands of the CCSSM and new SAT standards. While I used the lab to introduce standard deviations of random samples, the approach also could be used if your bivariate statistics unit is occurs later in your sequencing.
My class started a unit on sampling when we returned in January. They needed to understand how larger sample sizes tended to shrink standard deviations, but I didn’t want to just give them the formula
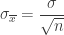
I know many teachers introduce this relationship by selecting samples with perfect square sizes and see the population standard deviations shrink by integer factors (quadruple the sample size = halve the standard deviation, multiply the sample size by 9 = standard deviation divides by 3, etc.), but I didn’t want to exert that much control. My students had explored data straightening techniques in the fall and were used to sampling and simulations, so I wanted to see how successfully they could leverage that background to “discover” the sample standard deviation relationship.
My AP Statistics students use TI Nspire CAS software on their laptops, so I wrote their lab using that technology. The lab could easily be adapted to whatever statistics technology you use in your class. You can download a pdf of my lab here.
LAB RESULTS AND REFLECTIONS
The activity drew samples from a normal distribution for which students were able to define their own means and standard deviations. Students could choose any values, but those who chose integers tended to make the later connections more easily.
Their first step was to draw 2500 different random samples of sizes n=1, 4, 10, 25, 50, 100. From each 2500 point data set, students computed sample means and standard deviations. In retrospect, I should have let students select all or most of their own sample sizes, but I’m still quite satisfied with the results. If you do experiment with different sample sizes, definitely run the larger potential sizes on your technology to check computation times.
One student chose 
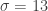

It was pretty obvious to her that no matter what the sample size, 

We had explored bivariate data-straightening techniques at the end of the fall semester, so she tried semi-log and log-log transformations to check for the possibilities that these data might be represented by an exponential or power function, respectively. Her semi-log transformation was still curved, but the log-log was very straight. That transformation and its accompanying linear regression are below.

Her residuals were small, balanced, and roughly random, so she knew she had a reasonable fit. From there, she used her CAS to transform (re-curve) the linear regression back to an equation for the original data.

It made sense that this resulting formula not only depended on the sample size, but also originally on the population standard deviation my student had earlier chosen to be 
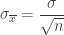
I know this formula is provided on the AP Statistics Exam, but the simulation, curve straightening, linear regression, and statistical confirmation of the formula were a great review and exercise. I hope you find it useful, too.

Pingback: Applications of Logarithm Algebra | CAS Musings