
This post shares what I think is one of the best, inclusive, data-oriented labs for a second year algebra class. This single experiment produces linear, quadratic, and exponential (and logarithmic) data from a lab my Algebra 2 students completed this past summer. In that class, I assigned frequent labs where students gathered real data, determined models to fit that data, and analyzed goodness of the models’ fit to the data. I believe in the importance of doing so much more than just writing an equation and moving on.
For kicks, I’ll derive an approximation for the coefficient of gravity at the end.
THE LAB:
On the way to school one morning last summer, I grabbed one of my daughters’ “almost fully inflated” kickballs and attached a TI CBR2 to my laptop and gathered (distance, time) data from bouncing the ball under the Motion Sensor. NOTE: TI’s CBR2 can connect directly to their Nspire and TI84 families of graphing calculators. I typically use computer-based Nspire CAS software, so I connected the CBR via my laptop’s USB port. It’s crazy easy to use.
One student held the CBR2 about 1.5-2 meters above the ground while another held the ball steady about 20 cm below the CBR2 sensor. When the second student released the ball, a third clicked a button on my laptop to gather the data: time every 0.05 seconds and height from the ground. The graphed data is shown below. In case you don’t have access to a CBR or other data gathering devices, I’ve uploaded my students’ data in this Excel file.

Remember, this is data was collected under far-from-ideal conditions. I picked up a kickball my kids left outside on my way to class. The sensor was handheld and likely wobbled some, and the ball was dropped on the well-worn carpet of our classroom floor. It is also likely the ball did not remain perfectly under the sensor the entire time. Even so, my students created a very pretty graph on their first try.
For further context, we did this lab in the middle of our quadratics unit that was preceded by a unit on linear functions and another on exponential and logarithmic functions. So what can we learn from the bouncing ball data?
LINEAR 1:
While it is very unlikely that any of the recorded data points were precisely at maximums, they are close enough to create a nice linear pattern.
As the height of a ball above the ground helps determine the height of its next bounce (height before –> energy on impact –> height after), the eight ordered pairs (max height #n, max height #(n+1) ) from my students’ data are shown below

This looks very linear. Fitting a linear regression and analyzing the residuals gives the following.

The data seems to be close to the line, and the residuals are relatively small, about evenly distributed above and below the line, and there is no apparent pattern to their distribution. This confirms that the regression equation, 
NOTE: You could reasonably easily gather this data sans any technology. Have teams of students release a ball from different measured heights while others carefully identify the rebound heights.
The coefficients also have meaning. The 0.673 suggests that after each bounce, the ball rebounded to 67.3%, or 2/3, of its previous height–not bad for a ball plucked from a driveway that morning. Also, the y-intercept, 0.000233, is essentially zero, suggesting that a ball released 0 meters from the ground would rebound to basically 0 meters above the ground. That this isn’t exactly zero is a small measure of error in the experiment.
EXPONENTIAL:
Using the same idea, consider data of the form (x,y) = (bounce number, bounce height). the graph of the nine points from my students’ data is:

This could be power or exponential data–something you should confirm for yourself–but an exponential regression and its residuals show

While something of a pattern seems to exist, the other residual criteria are met, making the exponential regression a reasonably good model: 
And you can get logarithms from these data if you use the equation to determine, for example, which bounces exceed 0.2 meters.

So, bounces 1-4 satisfy the requirement for exceeding 0.20 meters, as confirmed by the data.
A second way to invoke logarithms is to reverse the data. Graphing x=height and y=bounce number will also produce the desired effect.
QUADRATIC:
Each individual bounce looks like an inverted parabola. If you remember a little physics, the moment after the ball leaves the ground after each bounce, it is essentially in free-fall, a situation defined by quadratic movement if you ignore air resistance–something we can safely assume given the very short duration of each bounce.
I had eight complete bounces I could use, but chose the first to have as many data points as possible to model. As it was impossible to know whether the lowest point on each end of any data set came from the ball moving up or down, I omitted the first and last point in each set. Using (x,y) = (time, height of first bounce) data, my students got:

What a pretty parabola. Fitting a quadratic regression (or manually fitting one, if that’s more appropriate for your classes), I get:

Again, there’s maybe a slight pattern, but all but two points are will withing 0.1 of 1% of the model and are 1/2 above and 1/2 below. The model, 
LINEAR 2:
If your second year algebra class has explored common differences, your students could explore second common differences to confirm the quadratic nature of the data. Other than the first two differences (far right column below), the second common difference of all data points is roughly 0.024. This raises suspicions that my student’s hand holding the CBR2 may have wiggled during the data collection.

Since the second common differences are roughly constant, the original data must have been quadratic, and the first common differences linear. As a small variation for each consecutive pair of (time, height) points, I had my students graph (x,y) = (x midpoint, slope between two points):

If you get the common difference discussion, the linearity of this graph is not surprising. Despite those conversations, most of my students seem completely surprised by this pattern emerging from the quadratic data. I guess they didn’t really “get” what common differences–or the closely related slope–meant until this point.

Other than the first three points, the model seems very strong. The coefficients tell an even more interesting story.
GRAVITY:
The equation from the last linear regression is 
The slope of this line is -9.61. As this is a slope, its units are the y-units over the x-units, or (m/sec)/(sec). That is, meters per squared second. And those are the units for gravity! That means my students measured, hidden within their data, an approximation for coefficient of gravity by bouncing an outdoor ball on a well-worn carpet with a mildly wobbly hand holding a CBR2. The gravitational constant at sea-level on Earth is about -9.807 m/sec^2. That means, my students measurement error was about 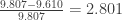
CONCLUSION:
Whenever I teach second year algebra classes, I find it extremely valuable to have students gather real data whenever possible and with every new function, determine models to fit their data, and analyze the goodness of the model’s fit to the data. In addition to these activities just being good mathematics explorations, I believe they do an excellent job exposing students to a few topics often underrepresented in many secondary math classes: numerical representations and methods, experimentation, and introduction to statistics. Hopefully some of the ideas shared here will inspire you to help your students experience more.
 , for which
, for which 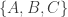 can be any arithmetic sequence. What do all members of this family have in common?
can be any arithmetic sequence. What do all members of this family have in common?
 to
to 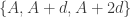 where d is the common difference for a generic arithmetic sequence with initial term A.
where d is the common difference for a generic arithmetic sequence with initial term A.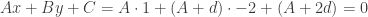 .
.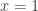 and solve for y to get
and solve for y to get 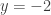 , proving that the y-coordinate for
, proving that the y-coordinate for 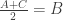 . This rewrites to
. This rewrites to 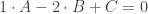 , so whenever
, so whenever 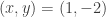 , then
, then  and another as
and another as 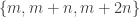 for any real values of a,d,m, and n. This leads to a system of equations:
for any real values of a,d,m, and n. This leads to a system of equations: 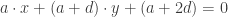 and
and  . If you have some younger students or if all the variables make you nervous,
. If you have some younger students or if all the variables make you nervous,  .
.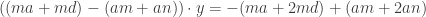
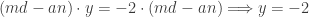
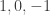 , the linear equation would be
, the linear equation would be 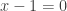 . Similarly, the sequence
. Similarly, the sequence 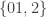 leads to
leads to 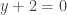 . Obviously, the only thing these two lines have in common is the point (1,-2). A proof of the property must still be established, but this is one of the fastest ways I’ve seen to identify the central property.
. Obviously, the only thing these two lines have in common is the point (1,-2). A proof of the property must still be established, but this is one of the fastest ways I’ve seen to identify the central property. as before, giving:
as before, giving: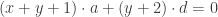 .
. . Similarly, (1,-2) can become (1,2) by translating up 4 units, giving
. Similarly, (1,-2) can become (1,2) by translating up 4 units, giving 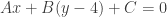 .
. on its graph. This is exactly why I share. Thanks, Doug!!
on its graph. This is exactly why I share. Thanks, Doug!!


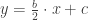 .
.
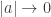 the parabolas’ vertices move infinitely far away from the y-axis, and as
the parabolas’ vertices move infinitely far away from the y-axis, and as  the vertices approach the y-axis. This also can be seen numerically from the generic x-coordinate of the vertex,
the vertices approach the y-axis. This also can be seen numerically from the generic x-coordinate of the vertex,  . For a fixed, non-zero value of b, the fraction representing the x-coordinate of the vertex increases in magnitude as
. For a fixed, non-zero value of b, the fraction representing the x-coordinate of the vertex increases in magnitude as  . The reason for the differences in distances between the points noted above is because
. The reason for the differences in distances between the points noted above is because  slower and slower, explaining the increasing density of the vertex trace points near the y-axis.
slower and slower, explaining the increasing density of the vertex trace points near the y-axis.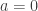 , the x-coordinate of the vertex is undefined. At that moment, the generic quadratic,
, the x-coordinate of the vertex is undefined. At that moment, the generic quadratic,  , a line. Graphing that line (the red dashed line below) against a trace of all possible parabolas as a varies, the degenerate parabola resulting when
, a line. Graphing that line (the red dashed line below) against a trace of all possible parabolas as a varies, the degenerate parabola resulting when  –a pretty extension on a connection suggested by
–a pretty extension on a connection suggested by 
